
티스토리 뷰
파이썬 크롤링 :: 네어버 웹툰의 순위 가져오기 :: BeautifulSoup, selenium, csv
모든 강의 자료 : www.codingnow.co.kr/
1. 실행영상
2. 설명
네이버의 웹툰사이트를 자동으로 실행하여 사이트에 표시되는 인기 웹툰 순위를 가져오는 파이썬 프로그래밍입니다.
comic.naver.com/webtoon/weekday.nhn
네이버 웹툰
매일매일 새로운 재미, 네이버 웹툰.
comic.naver.com
아래 빨강색으로 표시한 부분을 파이썬으로 가져올 겁니다.

3. 전체 소스
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import csv
print('-------------------------------------')
print('제작자 : https://blog.naver.com/cflab')
print('-------------------------------------')
def openDriver():
url = 'https://comic.naver.com/webtoon/weekday.nhn'
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get(url)
time.sleep(1)
return driver
def searchWebtoon(driver):
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all(class_='asideBoxRank', id="realTimeRankFavorite")[0]
mList = []
for i in range(1,11):
try:
searTag = f'rank{i:02d}'
title = tags.find(class_=searTag).a.text
print(f'순위 : {i}\n제목 : {title}\n')
mList.append([i, title])
except:
pass
driver.close()
return mList
def saveToFile(filename, mList):
with open(filename, 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerows(mList)
driver = openDriver()
mList = searchWebtoon(driver)
saveToFile('webtoon.csv', mList)4. 소스 설명
1. 여기에서 필요한 것을 import합니다.
크롬 웹브라우저를 실해하기 위해 webdriver를 가져오고, html을 분석하기 위해 BeautifulSoup를 그리고 delay를 주기 위해 time, 또한 CSV파일로 저장하기 위해 csv를 import합니다.
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import csv
2. def openDriver() 함수
크롬 웹드라이버를 다운로드 합니다. 아래 블로그 내용을 참고하세요.cflab.blog.me/222130893298
파이썬 기초 naver 급상승검색어 크롤링 하기 :: selnium, datalab
[프로그래밍언어] 파이썬 기초 naver 급상승검색어 크롤링 하기 :: selnium, datalab#파이썬 #python #파이...
blog.naver.com
웹 드라이버를 호출하고
driver = webdriver.Chrome()웹브라우저를 실행하여 웹페이지를 엽니다.
driver.get(url)웹페이지가 열릴때까지 기다려 줍니다. 여기서는 1초의 기다름을 줍니다.
time.sleep(1)3. searchWebtoon() 함수
웹페이지의 html을 가져오고 이것을 분석하여 순위를 list형태로 리턴해 줍니다.
이것은 웹페이지를 열어 BeautifulSoup으로 html을 가져오는 동작입니다.
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
html에서 순위를 가지고 있는 부분의 class를 가져옵니다.
tags = soup.find_all(class_='asideBoxRank', id="realTimeRankFavorite")[0]

list 형태로 리턴하기 위해서 선언합니다.
mList = []rank01~rank10까지의 데이타를 가져옵니다.
for i in range(1,11):
try:
searTag = f'rank{i:02d}'
title = tags.find(class_=searTag).a.text
print(f'순위 : {i}\n제목 : {title}\n')
mList.append([i, title])
except:
pass
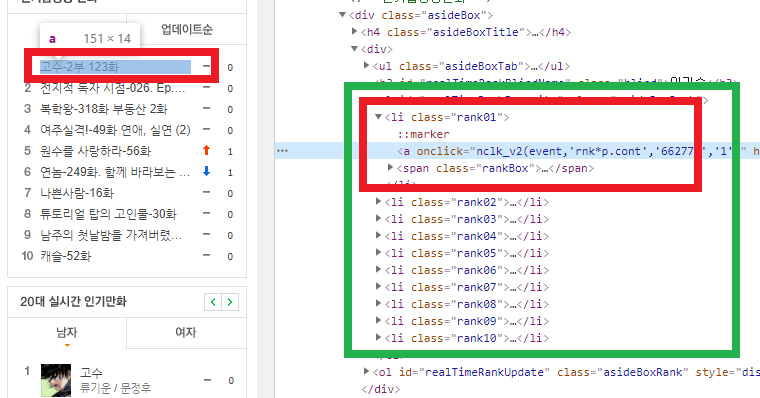
여기서 rank01, rank02... rank10 class 를 가져오기 위해 for loop를 사용하였습니다.
tags.find(class_='rank01').a.text
웹 브라우저를 종료합니다.
driver.close()4. saveToFile( ) 함수
이것은 list로 받은 data를 csv 파일로 저장합니다.
한글이 깨지는 것을 방지하기 위해 encoding='utf-8-sig' 을 추가합니다.
with open(filename, 'w', encoding='utf-8-sig', newline='') as f:
'파이썬 강의' 카테고리의 다른 글
| 파이썬 기초 활용 편 #간단한 게임 만들기 #가위바위보 게임 (0) | 2021.01.13 |
|---|---|
| 파이썬 기초 활용편 : : 학생의 총점, 최고, 최저, 평균 구하기 (0) | 2021.01.12 |
| 파이썬 기초 활용편 별 피라미드 출력하기 강의 :: 과정을 차근차근 설명합니다. (0) | 2021.01.12 |
| 파이썬 기초 :: 예외처리 와 쓰레드 :: try, except, thread (0) | 2021.01.11 |
| python :: 멜로차트 실시간 가져오기 크롤링 :: selenium, csv, BeautifulSoup (0) | 2020.11.17 |